Are reasoning benchmarks today actually reliable? Introducing the JustLogic benchmark
Logical reasoning is a critical component of Large Language Models (LLMs), and substantial research efforts in recent years have aimed to enhance their deductive reasoning capabilities. However, existing deductive reasoning benchmarks, which are crucial for evaluating and advancing LLMs, are inadequate.
The biggest flaw in deductive reasoning benchmarks: prior knowledge as a confounder
Existing benchmarks often fail to test deductive reasoning in isolation; models can use its world knowledge to answer questions that seemingly test for reasoning. For example, in FOLIO [1], a prominent benchmark for first-order logical reasoning, models are provided a context in order to ascertain the truth value of statements like:
The United States won the most medals in the last summer Olympic games.
While the goal is to test a model's ability to deductively reason the statement's truth value based on a given context, models can circumvent this process entirely by relying on prior knowledge instead.
Prior knowledge independence test
To empirically validate this claim, we developed a novel test for prior knowledge independence, which measures the influence of prior knowledge on reasoning benchmarks.
Experimental setup. Typically, reasoning benchmarks provide models with a context and a question; the model must then answer the question using the given context. For this test, however, we only provide the question without any context. This forces models to answer questions purely using prior knowledge.
If models cannot rely on prior knowledge to answer questions, their accuracy should be close to random probability. The converse is also true. The closer to random probability, the more prior knowledge independent the benchmark is, and therefore a more reliable test of deductive reasoning.
Results. As it turns out, prior knowledge is a major confounder in human-curated reasoning benchmarks like LogiQA 2.0 [2] and FOLIO. Synthetically-generated benchmarks like CLUTRR [3] and ProofWriter [4] are minimally affected by this.
| | |∆|↓ | Accuracy | Random Prob. |
|---|---|---|---|
| CLUTRR | 2.0 | 8.3 | 6.3 |
| ProofWriter | 4.7 | 37.0 | 33.3 |
| LogiQA 2.0 | 27.1 | 52.1 | 25.0 |
| FOLIO | 6.7 | 40.0 | 33.3 |
This is the uninintentional consequence of the human bias to align the question’s truth value with reality. So based on these results, we should simply use synthetic benchmarks to test for reasoning, right?
The problem with synthetic reasoning benchmarks
It isn't just sufficient to negate the influence of prior knowledge, the benchmark's setting must be sufficiently complex to mirror real-world questions, especially with regards to natural language complexity. And therein lies the problem with synthetic benchmarks.
| | Reading Difficulty | Vocabulary | No. of Domains |
|---|---|---|---|
| CLUTRR | 6.67 | 1396 | 1 |
| ProofWriter | 0.96 | 101 | ✖ |
| LogiQA 2.0 | 17.10 | 10004 | >10 |
| FOLIO | 18.75 | 4351 | >10 |
We measure natural language complexity with (i) reading difficulty, as measured by the Flesch-Kincard readability test [5], and (ii) lexical diversity, as measured by vocabulary & domain size. A domain is defined as any topic of interest, such as golf, computers, or traveling; Vocabulary size refers to the number of unique words in the dataset.
Synthetic benchmarks have vastly poorer natural language complexity, both in terms of depth and diversity of language. This makes such datasets prone to overfitting and does not realistically reflect LLMs' reasoning abilities in real-world conversations and tasks.
Introducing JustLogic
JustLogic is (i) highly complex, capable of generating a diverse range of linguistic patterns, vocabulary, and argument structures, (ii) prior knowledge independent, eliminating the advantage of models possessing prior knowledge and ensuring that only deductive reasoning is used to answer questions, and (iii) capable of in-depth error analysis on the heterogeneous effects of reasoning depth and argument form on model accuracy.
It is designed to tackle the shortcomings of exising deductive reasoning datasets.
How it works
JustLogic is synthetically generated, and the steps to generate each instance are as follows:
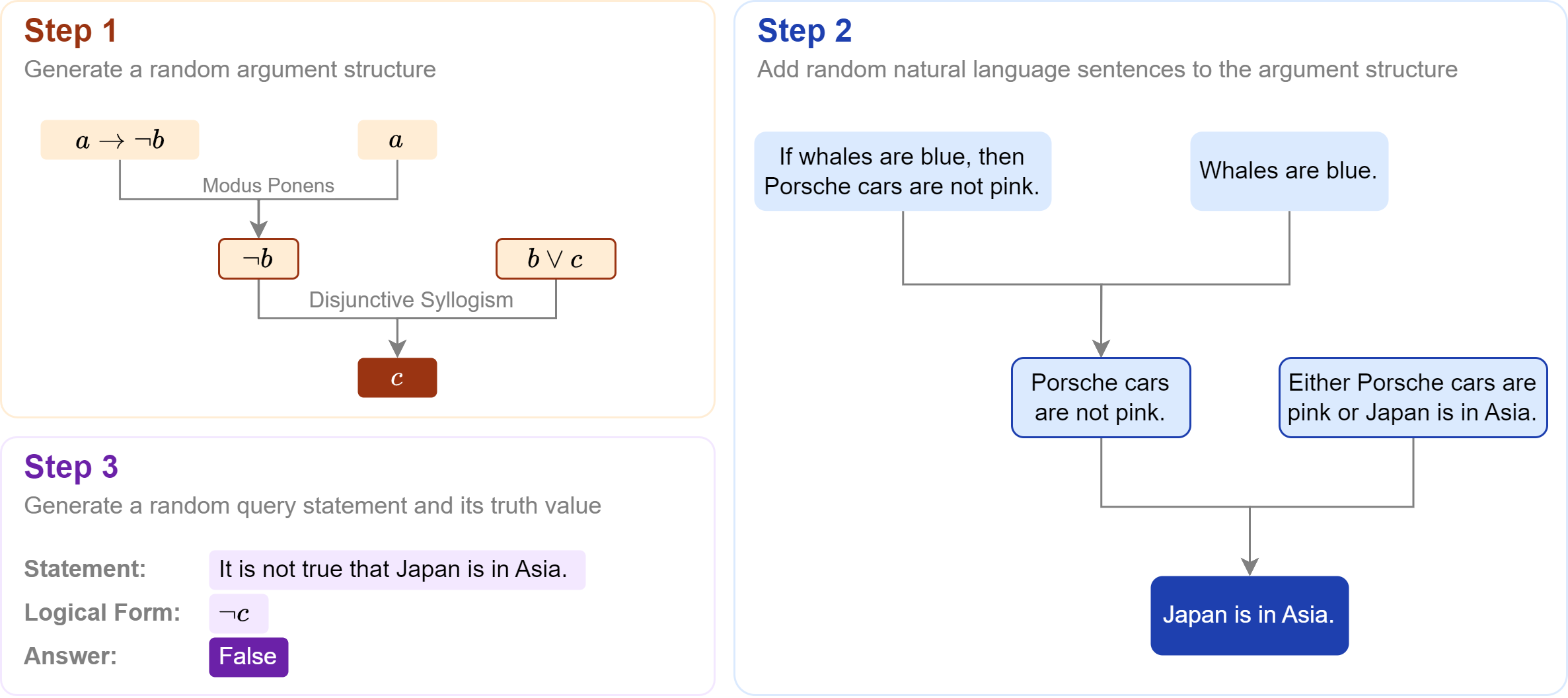
Step 1: Generate argument structure. Similar to synthetic datasets, the argument structure is randomly programmatically generated. The argument depth can be flexibly adjusted according to benchmarking needs. In our experiments, we generate arguments with depths of 1 to 7. Higher depths can be generated if needed.
Step 2: Add natural language statements to the argument structure. Logical forms, e.g. x → y, are first replaced using manually curated templates, e.g. "So long as x, then we know y. Then, the symbols, e.g. x and y, are replaced with random natural language statements from GenericsKB-Best [6], a database of 1M+ unique real-world sentences.
Note that these statements are generally factually inaccurate, e.g. the statement "If whales are blue, then Porsche cars are not pink.". This is intentional in order to ensure that if models attempt to use prior knowledge, they will arrive at the wrong answer.
At the same time, the use of real-world sentences increases the natural language complexity of JustLogic.
Step 3: Generate a query statement. The LLM’s task is to determine whether the given query statement is true, false, or uncertain based on the premises provided.
Futureproofing JustLogic
As the reasoning abilities of LLMs continue to improve, we expect LLMs to solve the existing JustLogic dataset eventually. We also expect benchmark leakage to eventually affect JustLogic.
JustLogic effectively tackles these issues by allowing new test sets to be generated trivially. To increase difficulty, argument depth can be increased to more than 7.
Proving its prior knowledge independence
Model accuracy for JustLogic, if the context is not provided, is extremely similar to random probability, thus showing that prior knowledge is virtually useless for answering JustLogic's questions. This is due to the synthetic nature of JustLogic.
| | |∆|↓ | Accuracy | Random Prob. |
|---|---|---|---|
| CLUTRR | 2.0 | 8.3 | 6.3 |
| ProofWriter | 4.7 | 37.0 | 33.3 |
| LogiQA 2.0 | 27.1 | 52.1 | 25.0 |
| FOLIO | 6.7 | 40.0 | 33.3 |
| JustLogic | 0.4 | 33.7 | 33.3 |
Natural language complexity
JustLogic is also more linguistically complex than other deductive reasoning datasets, even human-curated ones, thanks to its use of GenericsKB sentences.
| | Reading Difficulty | Vocabulary | No. of Domains |
|---|---|---|---|
| CLUTRR | 6.67 | 1396 | 1 |
| ProofWriter | 0.96 | 101 | ✖ |
| LogiQA 2.0 | 17.10 | 10004 | >10 |
| FOLIO | 18.75 | 4351 | >10 |
| JustLogic | 20.55 | 10557 | >10 |
LLM Performance on JustLogic
General observations:
- Chain-of-thought performs much better than zero-shot on reasoning tasks
- OpenAI o1-preview performs better than OpenAI o1 (this is tested using the chat interface)
- Most models underperform the human average; all models underperform the human ceiling.
| | Method | Accuracy (%) |
|---|---|---|
| Random Probability | 33.3 | |
| Llama3-8B | Zero-shot | 49.8 |
| Llama3-8B | CoT | 57.8 |
| Llama3-70B | Zero-shot | 53.1 |
| Llama3-70B | CoT | 64.6 |
| GPT-4o | CoT | 65.6 |
| OpenAI o1 | CoT | 64.3 |
| OpenAI o1-preview | CoT | 81.0 |
| Human Average | 73.0 | |
| Human Ceiling | 100.0 |
Error Analysis
A key advantage of JustLogic is its ability to analyze where exactly the model went wrong. We know the exact argument depth, type of argument, and linguistic features of each instance. For example, we can study the impact of argument depth and argument form on model performance:
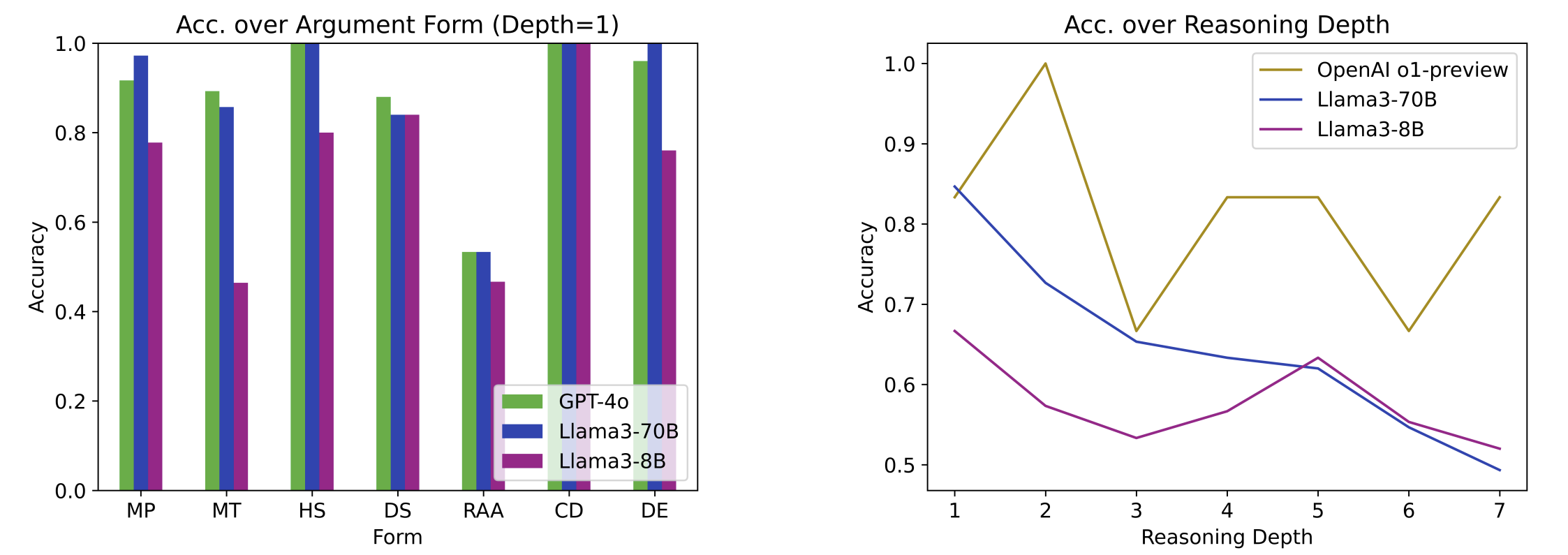
Observations:
- More commonly used argument forms, e.g. hypothetical syllogism, achieve considerably higher performance than less commonly used ones, e.g. reductio ad absurdum.
- As argument depth increases, model performance decreases.
Note that the volatility in OpenAI o1-preview's results is because only 42 questions were tested, 6 for each depth, due to chat restrictions.
Conclusion
JustLogic is a natural language deductive reasoning dataset that is (i) highly complex, (ii) prior knowledge independent, and (iii) capable of in-depth error analysis. These qualities are enabled by JustLogic’s dataset construction method: argument structures are synthetically generated, and natural language is programmatically incorporated via expression templates and a knowledge base. We empirically justify JustLogic’s merits: most LLMs underperform the human average and all significantly underperform the human ceiling. We demonstrate that JustLogic is a highly challenging, future-proof benchmark that is reliable and insightful for evaluating logical reasoning in LLMs.
Full details on JustLogic can be found in the paper..
References
[1] Han, S., Schoelkopf, H., Zhao, Y., Qi, Z., Riddell, M., Benson, L., Sun, L., Zubova, E., Qiao, Y., Burtell, M., Peng, D., Fan, J., Liu, Y., Wong, B., Sailor, M., Ni, A., Nan, L., Kasai, J., Yu, T., Zhang, R., Joty, S., Fabbri, A. R., Kryscinski, W., Lin, X. V., Xiong, C., and Radev, D. Folio: Natural language reasoning with first-order logic. arXiv preprint arXiv:2209.00840, 2022. URL https://arxiv.org/abs/2209.00840.
[2] Liu, H., Liu, J., Cui, L., Teng, Z., Duan, N., Zhou, M., and Zhang, Y. Logiqa 2.0—an improved dataset for logical reasoning in natural language understanding. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2023a.
[3] Sinha, K., Sodhani, S., Dong, J., Pineau, J., and Hamilton, W. L. Clutrr: A diagnostic benchmark for inductive reasoning from text. arXiv preprint arXiv:1908.06177, 2019.
[4] Tafjord, O., Mishra, B. D., and Clark, P. Proofwriter: Generating implications, proofs, and abductive statements over natural language. arXiv preprint arXiv:2012.13048, 2020.
[5] Kincaid, J. Derivation of new readability formulas (automated readability index, fog count and flesch reading ease formula) for navy enlisted personnel. Chief of Naval Technical Training, 1975.
[6] Bhakthavatsalam, S., Anastasiades, C., and Clark, P. Genericskb: A knowledge base of generic statements. arXiv preprint arXiv:2005.00660, 2020.